
ChatGPT medical triage hit the headlines in February 2026 — and not in a good way. The Nature Medicine study that drew the attention found one striking example: a patient with a three-day sore throat was told to see a doctor within 24 to 48 hours. That is an ENT case, and the advice is wrong in both directions — it’s unnecessary for most viral pharyngitis and dangerously slow for a deep neck infection.
ChatGPT Health launched in January 2026. The first independent safety evaluation appeared a month later. Most coverage stopped at the headline number — 51.6% of true emergencies under-triaged — without the clinical picture behind it. This piece translates what the finding actually means, where large language models systematically fail, and a simple rule I use with my own patients when they arrive with a screenshot of a chatbot conversation.
What the Nature Medicine Study Actually Measured
The study ran ChatGPT Health through a structured battery of triage scenarios and scored it against physician consensus (Nature Medicine, Feb 2026).
Three numbers matter:
- True emergencies were under-triaged 51.6% of the time — the bot recommended “see a doctor in 24 to 48 hours” instead of directing the patient to the emergency department.
- Non-urgent presentations were over-triaged 64.8% of the time — routine complaints were escalated to a physician visit that wasn’t necessary.
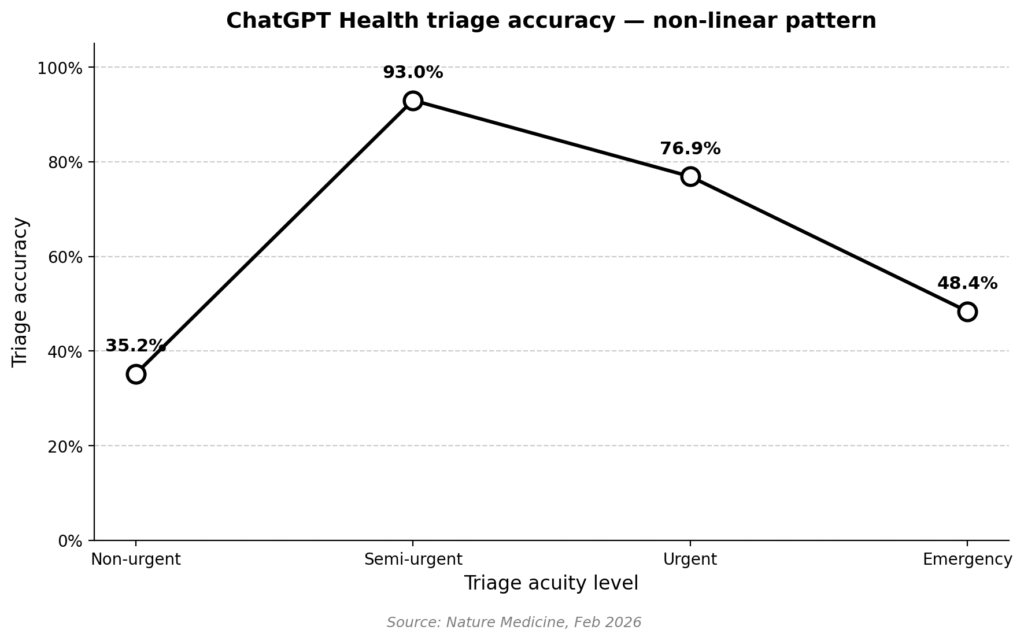
- In the middle band, accuracy was strong: 93.0% for semi-urgent, 76.9% for urgent.
Plot those points and the pattern is clearly non-linear. Accuracy peaks in the middle and collapses at the extremes.
Why the non-linear pattern
The authors attribute the pattern to central-tendency bias. Training data is dominated by ordinary presentations; the extremes — the unambiguous emergency and the clearly-fine complaint — are under-represented. When a model is uncertain, it averages toward the middle and recommends the middle-ground response, which happens to be “see a doctor within a day or two.”
That heuristic is catastrophic at the emergency end and wasteful at the benign end. It is, however, remarkably safe-looking in aggregate — which is why chatbot safety evaluations that don’t stratify by acuity tend to look better than they should.

Why a Sore Throat Is the Perfect Failure Case
Consider two patients who would both tell a chatbot, “I’ve had a sore throat for three days.”
Patient A — 24 years old, low-grade fever, symmetric erythema, no difficulty swallowing, no voice change. Viral pharyngitis. Supportive care. At-home management is reasonable.
Patient B — 24 years old, unilateral neck swelling, trismus (can barely open the mouth), drooling, a “hot-potato” voice. Possible deep neck infection. This is an emergency — airway compromise is a credible risk. The patient needs imaging to determine how far the infection has spread and to target an area for surgical drainage, if drainage is feasible. Cooperation with internal medicine or the ICU team is often necessary.
Same chief complaint. Same duration. The distinction lives entirely in physical findings a language model never sees.
The ENT red flags chatbots routinely miss
Two patterns are worth calling out explicitly — because a chatbot will not flag either reliably, and because both deteriorate on a clock:
- Trismus + drooling + muffled voice + acutely worsening neck pain with overlying skin color change → Deep neck infection is the working diagnosis until proven otherwise. The clinical team should be prepared for failed intubation and ready to proceed immediately to a surgical airway (tracheostomy) if intubation fails. SpO2 is not a reliable early warning in these patients — it can be the last vital sign to change. Breathing sounds and the patient’s own report of symptoms getting worse are more trustworthy signals.
- Epistaxis lasting more than 30 minutes in a patient on anticoagulation, or with cardiovascular risk (uncontrolled hypertension is the common one) → Procedural control is needed — not “see a doctor tomorrow.” Massive post-nasal drip in a patient with active nosebleed should raise alarm: posterior epistaxis, typically from the Woodruff plexus, is difficult to control and often requires general anesthesia.
Beyond these two, ENT presents too many variable situations to list in a single post. The broader point is this: emergencies in this field can deteriorate very rapidly — regardless of whether it is mid-afternoon or pre-dawn, regardless of how prepared the team happens to be. That volatility is, by itself, a reason not to delegate the triage decision to a chatbot.
How LLMs Fail at Clinical Reasoning — Not Just at Knowing
A separate 2026 evaluation of 21 large language models from the Mass General Brigham group found that models reach the correct final diagnosis more than 90% of the time when handed the full case — full history, full exam, all tests (JAMA Netw Open, Apr 2026). Their failure point is earlier: building a differential, choosing which tests to order, deciding when to escalate.
The same Nature Medicine team’s triage-focused analysis landed on the same conclusion from a different angle — LLMs have consistent blind spots when inputs are incomplete, ambiguous, or evolving. That is, of course, exactly the situation a patient is in when deciding whether to open a chatbot in the first place.
The practical translation: a chatbot can often recognize the right answer when you show it the answer. It cannot reliably arrive at the right answer from the sparse, noisy input that a worried patient can provide at home. The pattern is consistent: ChatGPT medical triage performs well on what’s typical and fails on what isn’t.
What Patients Can Actually Do With an AI Chatbot
AI chatbots have a useful role — just a narrower one than the marketing implies.
Reasonable uses
- Rephrasing a diagnosis you’ve already received so you understand it better.
- Preparing a list of questions to bring to your next clinic visit.
- Reading medication mechanisms, common side effects, and interaction warnings.
- Learning the definitions that make clinical conversations easier.
Unsafe uses
- Deciding whether to go to the emergency department.
- Interpreting a new, unexplained symptom.
- Triaging a child, an elderly patient, or anyone on significant medication.
- Replacing follow-up for a known condition.
The shorthand I give patients: use the chatbot after the doctor, not instead of the doctor.
Clinical Perspective
The picture that emerges from these 2026 studies is a coherent one. LLMs resemble a well-read junior resident who has memorized the textbook but hasn’t yet learned what a sick patient looks like. Strong on the typical. Dangerous on the atypical. And — because of how the training data is shaped — most confident exactly when they should be least confident.
The fix here is not better prompts or more specialized medical models, at least not in the short term. It is remembering what a chatbot is for: comprehension, not judgment.
Key Takeaways
- ChatGPT Health under-triaged 51.6% of true emergencies and over-triaged 64.8% of non-urgent cases in the Nature Medicine 2026 evaluation.
- LLM triage accuracy is non-linear: best for ordinary presentations, worst at the extremes where stakes are highest.
- The failure mode is central-tendency bias from training-data distribution, not a lack of medical facts.
- AI chatbots are acceptable for health literacy but unsafe for deciding whether to seek emergency care.
FAQ
Can I trust ChatGPT with medical symptoms?
Not for triage decisions. The Nature Medicine 2026 study found ChatGPT Health under-triaged more than half of true emergencies. It remains useful as a comprehension tool — reading about a diagnosis you’ve already received, preparing questions for a clinic visit, or understanding a medication — but it should not decide whether you seek emergency care.
Does ChatGPT Health know when to send me to the ER?
Inconsistently. It correctly identified unmistakable emergencies like stroke 100% of the time, but it missed 51.6% of broader emergency presentations. The missed cases tend to be the ones that look ordinary on the surface and become emergent on examination.
What did the Nature Medicine 2026 ChatGPT study find?
Triage accuracy followed a non-linear pattern. The model performed well on semi-urgent cases (93%) and poorly at both the emergency and non-urgent ends. The authors attribute this to central-tendency bias in training data — the extremes are under-represented, so the model defaults to a middle-ground recommendation.
Can ChatGPT differentiate a dangerous sore throat?
It can describe pharyngitis in general, but I am not confident it can distinguish a self-limited viral sore throat from a peritonsillar abscess or a deep neck infection. That distinction depends on physical findings and clinical experience a language model never observes.
What ENT symptoms should I never self-triage with a chatbot?
Sudden hearing loss, unilateral neck mass, dysphagia with weight loss, hoarseness beyond two weeks, trismus, epistaxis while on blood thinners, and several others. These need in-person evaluation regardless of what any chatbot suggests.
This article discusses AI chatbot performance for informational purposes. It is not medical advice. If you have concerning symptoms, seek evaluation from a qualified clinician.
Joonpyo Hong, MD is a board-certified otolaryngologist practicing in Korea. This article reflects his clinical interpretation of published research and does not constitute individual medical advice.
References
- Ramaswamy A, Tyagi A, Hugo H, et al. ChatGPT Health performance in a structured test of triage recommendations. Nat Med. 2026 Feb 23. doi: 10.1038/s41591-026-04297-7. PMID: 41731097.
- Rao AS, Esmail KP, Lee RS, et al. Large Language Model Performance and Clinical Reasoning Tasks. JAMA Netw Open. 2026 Apr 1;9(4):e264003. doi: 10.1001/jamanetworkopen.2026.4003. PMID: 41973425; PMCID: PMC13077515.
For more interesting contents:
https://curiousmd.com/deviated-septum-diagnosis-ai/
https://curiousmd.com/anti-tslp-antibody-nasal-polyps/
You can link out to:
https://www.nature.com/articles/s41591-026-04297-7
https://jamanetwork.com/journals/jamanetworkopen/fullarticle/10.1001/jamanetworkopen.2026.4003