
How AI voice cloning works has become a clinical question. Fifteen seconds — that is all OpenAI’s Voice Engine reportedly needs to clone a person’s voice. As of May 2026, Tennessee’s ELVIS Act and California’s AI disclosure laws have taken effect, while the federally proposed NO FAKES Act—which remains pending in the Judiciary Committee—continues to drive the legal reshaping of commercial synthetic voice usage. A natural ENT clinic question follows: “Doctor, can someone copy my voice from a phone call?”
This article walks through what AI voice cloning actually replicates, why your voice is anatomically unique, where the technology helps patients, and where it gets dangerous. The ENT lens is rarely applied to this conversation — but it should be.
What Makes Your Voice Unique?
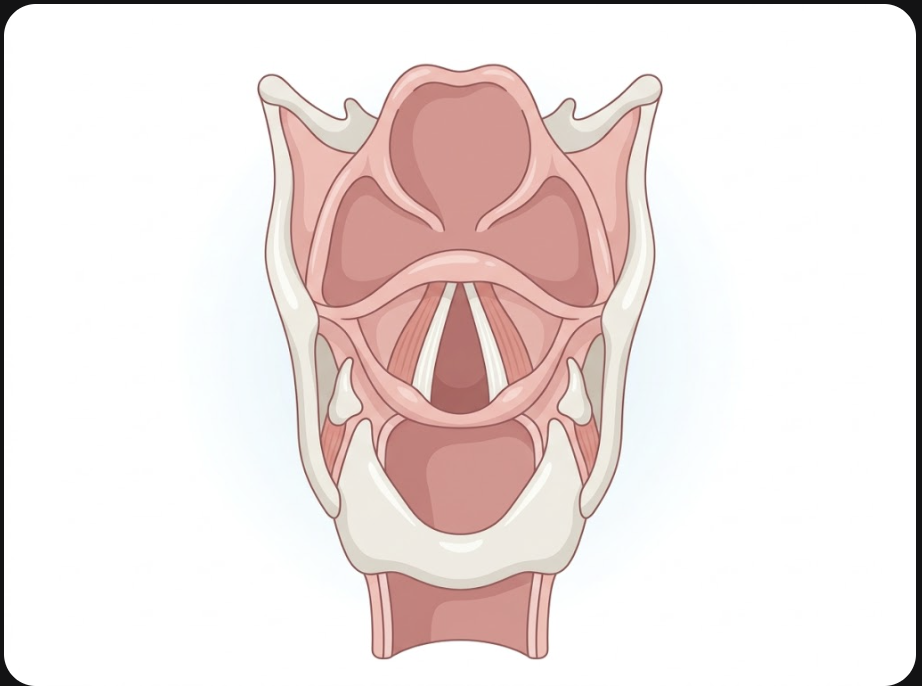
Your voice is not just a sound. It is the acoustic output of two distinct anatomical systems working together. The vocal folds in the larynx vibrate to produce a fundamental frequency (F0) — averaging around 120 Hz in adult men and 210 Hz in adult women, with normal ranges spanning roughly 85–180 Hz and 165–255 Hz respectively. The vocal tract above the folds — pharynx, oral cavity, nasal passages — shapes that buzz into specific resonant peaks called formants (F1, F2, F3).
Three measurable quantities reveal vocal health and identity. Jitter captures cycle-to-cycle frequency variation. Shimmer captures cycle-to-cycle amplitude variation. Harmonic-to-noise ratio (HNR) quantifies how much of the sound is periodic vibration versus turbulent noise. Patients with vocal nodules, polyps, or paralysis show elevated jitter, elevated shimmer, and reduced HNR compared with healthy controls [Teixeira, Jitter Shimmer and HNR Parameters, 2013].
Your specific combination of laryngeal anatomy, neuromuscular control, and vocal tract geometry creates an acoustic signature. That signature is what AI learns.
How AI Voice Cloning Works in 15 Seconds
To understand how AI voice cloning works, picture a three-stage neural pipeline descended from the SV2TTS architecture introduced by Jia and colleagues at Google in 2018 and refined by later systems such as VALL-E (Microsoft, 2023), Tortoise-TTS, and ElevenLabs’ commercial models.
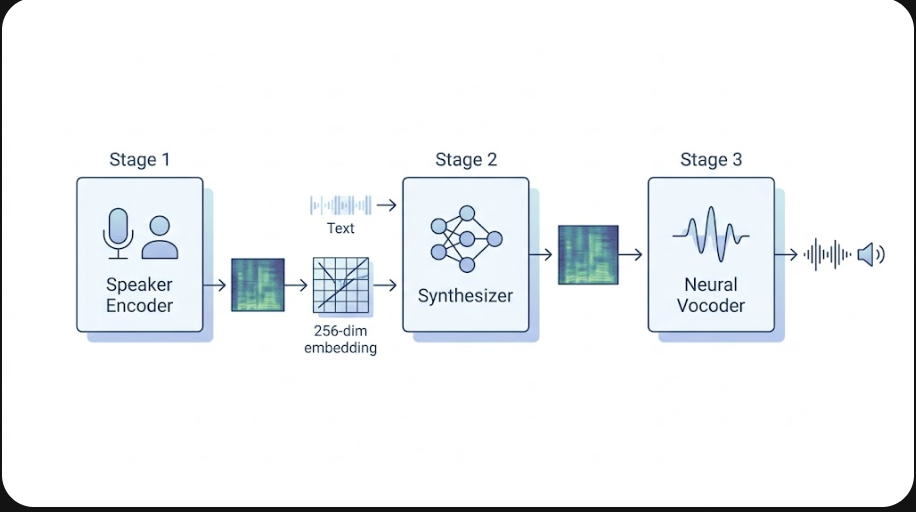
Stage 1 — Speaker encoder. The system first converts your audio sample to a mel-spectrogram, a time-frequency representation that approximates how the cochlea decomposes sound. A speaker encoder network — usually a stack of LSTM or transformer layers trained on tens of thousands of speakers — compresses that spectrogram into a fixed-length speaker embedding of roughly 256 dimensions. This embedding is a numerical fingerprint of who is talking, independent of what is being said.
Stage 2 — Synthesizer. A text-to-mel model (Tacotron 2, FastSpeech 2, or a transformer like VALL-E) takes the target text plus your speaker embedding and predicts a new mel-spectrogram in your voice. Recent systems treat speech generation as a language modeling problem: VALL-E tokenizes audio into discrete codec tokens and predicts them autoregressively, much like a large language model predicts text tokens. Diffusion-based synthesizers (NaturalSpeech 2, Voicebox) iteratively refine noisy spectrograms toward clean speech.
Stage 3 — Neural vocoder. A vocoder such as HiFi-GAN or WaveNet converts the predicted spectrogram back into a raw waveform at 24 kHz or higher. The vocoder is what makes modern clones sound natural rather than mechanical — early concatenative TTS sounded robotic precisely because it lacked this learned waveform model.
Few-shot cloning works because the heavy lifting is done in pre-training. The speaker encoder has already learned, across thousands of voices, what dimensions distinguish humans. Your 15-second sample only needs to locate you in that pre-learned space. Commercial tools (ElevenLabs, OpenAI Voice Engine, Resemble, Microsoft VALL-E) advertise viable clones from 3–10 seconds of clear audio.
What the model captures well: average pitch and pitch range, vowel formants, speaking tempo, regional accent, and characteristic breathing rhythms. What it captures poorly: emotionally driven micro-variations, paralinguistic signals like laughter or hesitation, and subtle neuromuscular tremor that varies with fatigue or illness. Detection research notes that pause structure and prosodic transitions remain residual giveaways in many clones [Khanjani, Investigation of Deepfake Voice Detection Using Speech Pause Patterns, 2024].
Voice Cloning in Medicine — The Good Side
Voice cloning is not just a security story. For some ENT patients, it is restorative.
Voice banking before laryngectomy. Patients facing total laryngectomy for advanced laryngeal cancer can record their voice pre-operatively. Modern text-to-speech synthesis trained on those recordings can later serve as an alternative communication means [Halpern, Text-to-speech Synthesis as an Alternative Communication Means After Total Laryngectomy, 2020]. The synthetic voice sounds recognizably like the patient — a meaningful gain over robotic electrolarynx output.
Progressive voice loss. Patients with amyotrophic lateral sclerosis, Parkinson’s disease, or progressive bulbar palsy can bank a healthy voice early, then deploy it later through assistive communication devices. ElevenLabs began offering free professional voice clones to laryngectomy patients in 2024.
Clinical Perspective. For a patient facing total laryngectomy, voice rehabilitation has historically meant choosing between esophageal speech, electrolarynx, or tracheoesophageal puncture (TEP) prosthesis. AI voice banking remains a research-stage idea rather than routine clinical care — where reimbursement, regulatory pathways, and integration with assistive devices are not yet established. The concept is promising, but it is not yet a recommendation I would make at the bedside.
The Dark Side — Deepvoice Scams and Detection
Same technology, opposite use case.
In 2020, a UAE bank manager wired $35M after a voice-cloned phone call from someone he believed was a corporate director. In 2024, a Hong Kong finance worker at a multinational firm was duped on a deepfake video call into authorizing $25M in transfers. Korean media reports of deepvoice phishing have risen sharply through 2025.
The detection problem is severe. A 2024 study found that humans correctly identified AI-cloned voices roughly 60% of the time, with chance being 50% [Barrington, People Are Poorly Equipped to Detect AI-Powered Voice Clones, 2024]. Algorithmic detectors do better but face an arms race against generative models that improve every month [Almutairi, Audio Deepfake Detection: What Has Been Achieved and What Lies Ahead, 2024].
Practical implication: the trusted voice on the phone is no longer trustworthy by itself. Verification must be procedural — callback to a known number, code phrases agreed in advance — not perceptual.
Clinical Perspective
Consider three cases worth thinking through:
Case 1 — A user worried about voice clips on social media. For most people, the practical risk of targeted cloning fraud is low; voice cloning scams typically pursue people with money or authority to authorize transactions. For executives, public figures, and voice professionals, the risk is real, and procedural verification — callback to a known number, agreed code phrases — is the only reliable defense.
Case 2 — A patient asking whether voice analysis can pre-empt symptoms. In research settings, yes. Acoustic features (jitter, shimmer, HNR) shift with vocal fold pathology, Parkinson’s disease, and depression. This is screening, not diagnosis. Symptomatic patients still need laryngoscopy and clinical evaluation.
Case 3 — A patient wondering whether to bank their voice before any throat surgery. For total laryngectomy candidates, voice banking is a theoretically attractive concept but not yet standard care. For routine procedures, the voice is not at meaningful risk and banking is not warranted.
Key Takeaways
- AI voice cloning extracts a “speaker embedding” of pitch, formants, and prosody from 3–15 seconds of audio, then generates new speech conditioned on that embedding.
- Humans detect AI-cloned voices at approximately 60% accuracy — barely better than chance — making procedural verification (callback, code phrases) more reliable than perceptual judgment.
- Voice banking before total laryngectomy is an emerging option that lets patients retain a recognizable synthetic version of their own voice post-operatively.
- Acoustic perturbation measures (jitter, shimmer, HNR) reflect vocal fold health and are altered by laryngeal pathology — the same features AI uses to clone are the features clinicians use to diagnose.
FAQ
How does AI clone someone’s voice? AI clones a voice by training a neural network on acoustic features — pitch, formants, prosody, breathing — extracted from a short audio sample. The model produces a compact speaker embedding, then generates new speech conditioned on that embedding. Quality scales with sample length, recording clarity, and the size of the model’s pre-training data.
How long of a voice sample does AI need? Modern systems advertise viable clones from 3–10 seconds of clear audio; OpenAI Voice Engine has been demonstrated with about 15 seconds. Better cloning typically requires longer, cleaner samples free of background noise and overlapping speakers.
Can voice analysis detect medical conditions? Yes, in research and increasingly in early clinical applications. Changes in jitter, shimmer, and harmonic-to-noise ratio can flag vocal fold lesions, paralysis, Parkinson’s disease, and other conditions. Voice analysis is a screening tool, not a substitute for laryngoscopy or neurological examination.
Is AI voice cloning illegal? It depends on jurisdiction and use. In the US, regulation is currently state-led — Tennessee’s ELVIS Act (2024) prohibits unauthorized voice cloning of artists, and California, New York, Illinois, and Texas have similar protections. The federal NO FAKES Act has been proposed but not yet enacted. Cloning a person’s voice for fraud or non-consensual commercial use is illegal in most jurisdictions; personal use and consented cloning are generally legal.
Can you tell if a voice is AI-generated? Average humans correctly identify AI-cloned voices about 60% of the time, only modestly above chance (Barrington, 2024). Algorithmic detectors perform better but face an ongoing arms race with newer generative models. Procedural verification — callback to a known number — is more reliable than perceptual detection.
Should I record a voice baseline before throat surgery? For routine ENT procedures, no — your voice is not at meaningful risk. For total laryngectomy candidates (or head and neck surgeries that can affect larynx anatomy), voice banking is a theoretically appealing option, but it is not yet integrated into routine clinical pathways. Patients interested in the concept should discuss research-stage availability with their care team.
Joonpyo Hong, MD is a board-certified otolaryngologist practicing in Korea. This article reflects his clinical interpretation of published research and does not constitute individual medical advice.
References
- Barrington S, Farid H. People are poorly equipped to detect AI-powered voice clones. Scientific Reports. 2025.
- Almutairi Z, Elgibreen H. Audio Deepfake Detection: What Has Been Achieved and What Lies Ahead. Sensors. 2024.
- Khanjani Z, Watson G, Janeja VP. Investigation of Deepfake Voice Detection Using Speech Pause Patterns: Algorithm Development and Validation. JMIR Biomedical Engineering. 2024.
- Halpern BM, Feng Y, van Son R, van den Brekel M, Scharenborg O. Text-to-speech synthesis as an alternative communication means after total laryngectomy. B-ENT. 2020.
- Teixeira JP, Oliveira C, Lopes C. Vocal Acoustic Analysis – Jitter, Shimmer and HNR Parameters. Procedia Technology. 2013.
- Sharma M, Murthy AS. Acoustic Voice Analysis of Normal and Pathological Voices in Indian Population Using Praat Software. Indian Journal of Otolaryngology and Head and Neck Surgery. 2023.
For more interesting contents:
https://curiousmd.com/ai-laryngeal-cancer-detection/
https://curiousmd.com/neuralink-voice-speech-first/
https://curiousmd.com/how-emotional-tts-works-ent-perspective/
Link out to:
https://www.nature.com/articles/s41598-025-94170-3
https://arxiv.org/abs/1806.04558
https://arxiv.org/abs/2301.02111