Type [sigh] into ElevenLabs v3 today and the AI actually sighs — air escapes the model’s “vocal tract” with the same slack-glottis breathiness that any otolaryngologist would recognize on a flexible scope. A year ago, this kind of emotional TTS was impossible. Now it sounds uncanny.
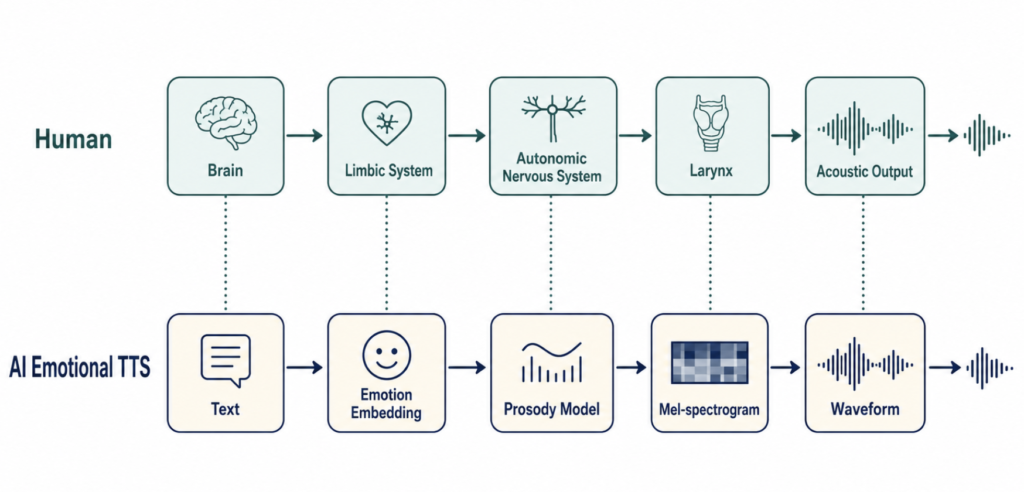
The engineers behind these new emotional text-to-speech (TTS) systems are not inventing anything new. They are reverse-engineering the larynx. Every acoustic parameter that emotional TTS models learn to manipulate — fundamental frequency, jitter, shimmer, harmonic-to-noise ratio, glottal pulse shape — is what voice clinics measure every week with tools like Praat or MDVP. This article walks through that parallel: what happens in the human larynx when emotion takes hold, how AI now models the same changes, where the technology is already being used, and where the gap between human and synthetic voice remains widest.
What Actually Changes in Your Voice When You Feel Emotion
The pipeline inside the larynx
The voice changes long before the speaker decides to “sound” angry or sad. Limbic activation routes through the periaqueductal grey, which feeds the laryngeal motor cortex and the central autonomic network in parallel. The result is a coordinated shift in two systems at once: respiratory drive (subglottic pressure, expiratory flow) and intrinsic laryngeal muscle tone [González-García M, Central Autonomic Mechanisms Involved in the Control of Laryngeal Activity and Vocalization, 2024].
The cricothyroid muscle, innervated by the external branch of the superior laryngeal nerve, stretches the vocal fold and is the primary determinant of pitch (F0). Sympathetic arousal increases its tone. The thyroarytenoid contracts and shortens the fold. Together, these tiny adjustments change vibratory frequency by a noticeable amount — typically on the order of a few tens of hertz in adult speakers — which the listener perceives as a “raised” or “lowered” voice. Experimental sympathetic activation produces measurable changes in intrinsic laryngeal muscle activity in healthy speakers [Helou LB, Intrinsic laryngeal muscle activity in response to autonomic nervous system activation, 2013].
What is interesting from a clinical standpoint is that this same circuit, chronically activated, is what produces muscle tension dysphonia. The autonomic-laryngeal coupling that produces an angry voice in a healthy speaker is the same coupling that produces a strained, effortful voice in a stressed patient with primary MTD [Demmink-Geertman L, Nonorganic habitual dysphonia and autonomic dysfunction, 2002]. Normal emotional vocalization sits on a continuum with pathology, separated mainly by duration and reversibility.
The four acoustic “knobs” the brain turns
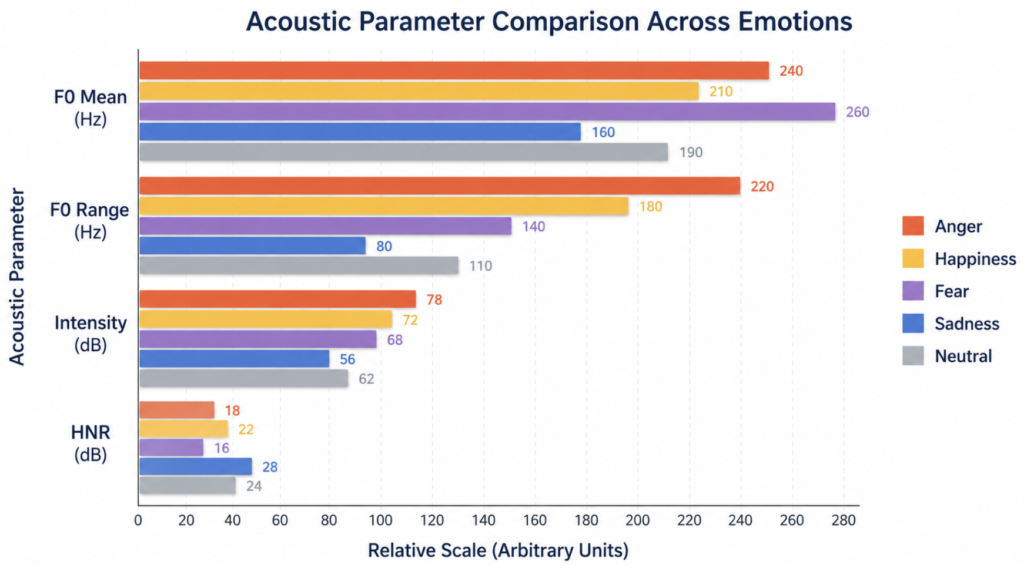
In voice clinics, a familiar set of parameters is extracted from a sustained vowel or a connected speech sample. The same four features account for most emotional variation in voice:
- F0 (fundamental frequency, or pitch) — Set by vocal fold tension and length. Higher with sympathetic arousal.
- F0 range and variability — The melodic contour of an utterance. Wider in high-arousal states, flatter in low-arousal states.
- Intensity — A function of subglottic pressure and glottal closure. Reflects respiratory drive.
- Voice quality — Captured by jitter (cycle-to-cycle pitch perturbation), shimmer (amplitude perturbation), and harmonic-to-noise ratio (HNR). Tense, irregular phonation raises jitter and shimmer; breathy phonation lowers HNR.
A fifth axis sits in the vocal tract itself: formant frequencies shift slightly with articulatory effort, which is why an angry speaker often hyperarticulates while a sad speaker mumbles.
How Each Emotion Reshapes the Voice
Decades of acoustic work — Banse and Scherer’s reference study being the most cited — have given us reasonably consistent acoustic profiles for the major emotions [Banse R, Acoustic profiles in vocal emotion expression, 1996]. A more recent meta-analysis covering both vocal expression and music performance found the patterns hold across cultures and even across modalities [Juslin PN, Communication of emotions in vocal expression and music performance, 2003].
| Emotion | F0 (mean) | F0 range | Speech rate | Intensity | Voice quality | Articulation |
|---|---|---|---|---|---|---|
| Anger | High | Wide, large excursions | Fast | Loud | Tense, irregular | Hyper-articulated |
| Happiness | High | Wide, fluctuating | Fast | Loud | Modal, “bright” | Clear |
| Fear | High | Narrower than anger | Variable | Variable | Breathy, jittery | Reduced |
| Sadness | Low | Narrow, flat | Slow | Quiet | Breathy, low HNR | Reduced precision |
| Neutral | Mid | Moderate | Mid | Mid | Modal | Standard |
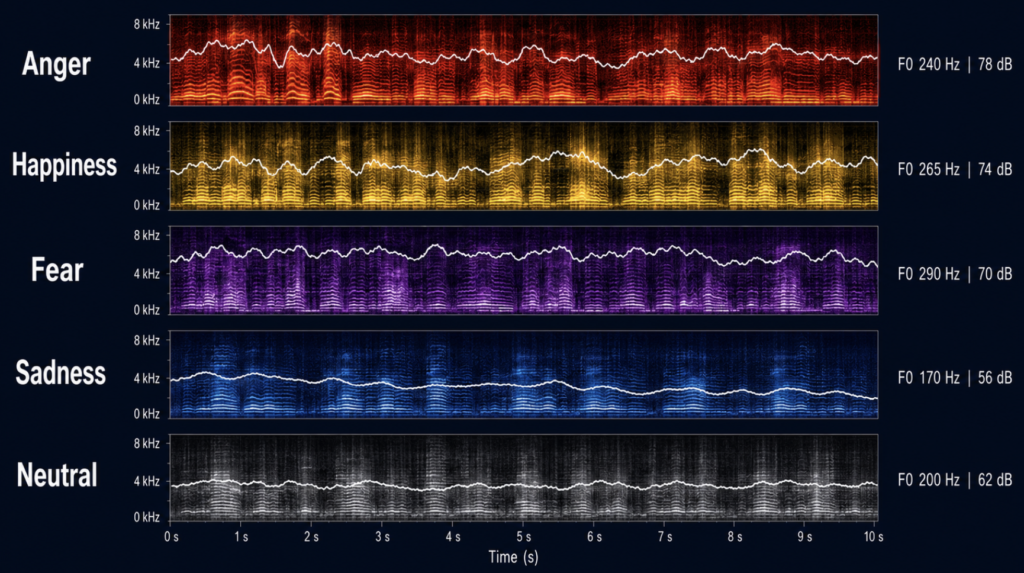
A few clinical observations worth pulling out of that table.
Anger and happiness sound surprisingly similar acoustically. Both are high-arousal states, and listeners — including trained ones — confuse them more often than the cultural stereotype suggests. The valence dimension (positive vs. negative) shows up mainly in voice quality and spectral tilt, not in pitch or rate.
Sadness looks like hypofunctional dysphonia on paper. Low F0, narrow range, low HNR, breathy quality — these are the same descriptors that appear in voice clinic charts for patients with vocal fold bowing or presbylarynx. The mechanism is different (parasympathetic dominance and reduced respiratory effort versus age-related atrophy), but the acoustic signature overlaps.
Fear is the most variable. A person can freeze, whisper, or scream when frightened, and the acoustic profile depends entirely on which behavior wins out. EEG work suggests that listeners actually pick up on intensity and pitch within the first 200 ms of an emotional vocalization, before any conscious recognition [Tang Y, Acoustic Features of Emotional Vocalizations Account for Early Modulations of Event-Related Brain Potentials, 2026].
How AI Reproduces This — The Engineering Side
The history of TTS has moved through three eras. The first was concatenative — stitch together pre-recorded phonemes, which sounded like a robot reading a phonebook. The second was parametric, using hidden Markov models to interpolate prosody mathematically, which fixed the joins but left a flat affect. The third era, neural TTS, started around 2017 with Tacotron and now dominates: a deep network learns to map text directly to a mel-spectrogram, and a separate vocoder turns that into a waveform.
Within neural TTS, emotion is added in one of three ways.
Label-based emotional TTS trains on a corpus where each utterance carries a tag — “happy,” “sad,” “angry” — and the model learns a separate prosody pattern per tag. This is the simplest approach and the easiest to control, but the output sounds posed, like an actor reading from a card.
Reference-based style transfer takes an audio clip as a prompt and extracts a “style embedding” — most famously through Global Style Tokens (GST) — which is then applied to new text. Models like XTTS-v2 use this approach. The advantage is fine-grained transfer of a specific speaker’s emotional rendering. The disadvantage is that the embedding mixes emotion with speaker identity and prosodic habit, so isolating just the emotion is hard.
Context-aware emotional TTS is the 2024–2026 leap. Instead of asking the user to pick an emotion label, the model reads the text and infers what the emotional register should be. Hume AI’s Octave generates prosody, pace, and inseparation directly from the semantic content of the text. ElevenLabs v3 introduces bracketed audio tags — [sigh], [whispers], [laughs] — that the model treats as first-class generation tokens rather than text to read aloud. OpenAI’s gpt-4o-mini-tts allows steerability through natural-language descriptions of the desired delivery. The underlying machinery is similar to a large language model’s: the network has internalized statistical associations between semantic content and acoustic realization from massive corpora.
Clinical Perspective. What the AI is actually predicting, in the end, is the same set of variables a voice clinician measures: an F0 contour, an energy envelope, segmental durations, a spectral shape, and increasingly the glottal pulse waveform itself. A 2026 framework called Physiology-Informed Vocal Spectrotemporal Representations explicitly trains the model on glottal pulse shape, citing — in the engineers’ own words — that “heightened emotional tension increases vocal fold adduction, resulting in a steeper glottal pulse waveform.” Voice scientists have been describing that exact relationship in patients for forty years. The engineers found it independently because it is the truth of the physiology.
Where Emotional TTS Is Already Being Used

Emotional rendering is not a research demo. It has unlocked real applications across five domains, several of which sit squarely in otolaryngology’s territory.
Voice banking and post-laryngectomy communication
This is the clearest clinical use case. Total laryngectomy, still standard care for advanced laryngeal cancer, strips a patient of natural phonation. Traditional alternatives — the electrolarynx and tracheoesophageal voice prosthesis — restore intelligibility but produce a flat, mechanical sound that erases emotional identity.
Voice banking, the practice of recording a patient’s voice before surgery to build a personalized synthetic voice, has existed since the 1990s, but early systems were monotone. Modern emotional TTS changes this. In a study of 61 total laryngectomy patients offered personalized speech synthesis as augmentative communication, the authors concluded that such voice rehabilitation “should be offered to all patients who are deemed eligible” [Lorenc A, Text-to-speech synthesis as an alternative communication means after total laryngectomy, 2020]. More recent work has shown HiFi-GAN-based voice banking to be technically viable for amyotrophic lateral sclerosis patients, with the focus shifting from intelligibility to the emotional and personal resonance of the synthetic voice.
In Korean clinical practice, voice banking is not yet a standard pre-operative consultation item, and tracheoesophageal speech, esophageal speech, and the electrolarynx remain the primary options. For younger patients or those for whom vocal identity carries significant weight, voice banking with emotional rendering is an emerging option worth discussing alongside standard speech and swallowing evaluation.
Audiobook narration and long-form content
The audiobook industry has been the most visible commercial beneficiary. The global audiobook market reached approximately $10 billion in 2025 and is growing at over 25% annually. AI-driven TTS has reduced production costs by more than 80% and compressed timelines from months to weeks. The hard requirement is not single-utterance convincingness but consistent emotional arcs across 8–12 hours of content — voice quality that drifts between chapters destroys the listening experience. Long-form tools released in 2025–2026 (Fish Audio Story Studio, ElevenLabs long-form models) are built specifically around this constraint.
Mental health and empathic AI
Voice-based emotional AI has become a notable modality in digital mental health. Tools such as Wysa, Woebot, Earkick, and Hume AI’s empathic voice interface use emotionally calibrated speech to deliver cognitive-behavioral exercises, mood tracking, and supportive dialogue. Early randomized trials — for example, a short-term study of the Chinese empathic agent Emohaa — show promising reductions in self-reported distress compared with controls [Sabour S, A chatbot for mental health support: exploring the impact of Emohaa on reducing mental distress in China, 2023], but evidence is still limited to a few short-term trials in selected populations, and long-term clinical efficacy in diverse or severely affected groups remains uncharacterized. The proposed mechanism is that a warm, responsive voice raises user engagement and perceived alliance — both correlates of therapeutic outcome.
Gaming, virtual characters, and accessibility
Game studios use emotional TTS to give non-player characters dynamic, context-appropriate dialogue without recording every line with a voice actor. For accessibility, screen readers with emotional rendering reduce listening fatigue for visually impaired users navigating long documents — a flat synthetic voice over a 400-page legal contract is genuinely punishing, while an emotionally varied one is not.
Customer service and conversational agents
Call-center AI agents (Inworld, ElevenLabs Conversational AI 2.0, others) now hold real-time interactions while calibrating tone to the customer’s emotional state: soothing when the caller is frustrated, energetic when the caller is enthusiastic. Whether this is welcomed or experienced as manipulative depends on disclosure and context — an open question for both regulators and clinicians who care about the line between rapport and persuasion.
Where AI Still Falls Short
Five gaps where the synthesis falls short of what a real human larynx produces stand out.
Mixed and transitional emotions. A real sentence often carries two emotions in sequence — annoyance fading to resignation, surprise tipping into relief. AI emotional TTS still tends to lock in a single emotion per utterance. Recent hierarchical models, controlling emotion at the word and phoneme level, are improving this, but the transitions sound stepped rather than continuous.
Idiosyncratic voice quality. Jitter, shimmer, and HNR are partly a function of the individual’s laryngeal anatomy and autonomic reactivity. A person with a slightly asymmetric vocal fold, a higher resting laryngeal tone, or a more reactive sympathetic system will have an emotional signature unlike anyone else. Generalized models smooth this away.
Paralinguistic events. Sighs, sobs, vocal tremor, glottal fry, audible inhalation — these arise from laryngeal-respiratory coupling that is difficult to model from text alone. ElevenLabs v3 tags are a workaround, not a solution; the timing rarely lands where a human would naturally place it.
Cross-cultural prosody. Korean and Japanese encode a substantial portion of emotional information in sentence-final particles and pitch contours, which English-centric training data underrepresents. Models that sound emotionally rich in English can sound flat in Korean for reasons that have nothing to do with the model and everything to do with the corpus.
Pathology blind spot. Sad voice and hypofunctional dysphonia overlap on the acoustic profile. Anxious voice and muscle tension dysphonia share another. Acoustic features alone can be insufficient to distinguish emotion from pathology in some cases — which means that a purely acoustic emotion classifier risks misreading pathology as mood. In the clinic, this is what stroboscopy, aerodynamic measurements, perceptual evaluation, and the patient’s history are for; the acoustic signal was never meant to carry the diagnostic weight on its own.
Why This Matters in the Clinic
Voice rehabilitation may eventually use emotional TTS the way physiatrists use motion capture — as a reference for what a healthy emotional voice looks like, against which a patient’s recovery can be benchmarked. The reverse is also true: the AI field is, almost accidentally, re-validating the parameters that voice scientists have argued for since the 1990s. When an emotional TTS model improves by adding glottal pulse modeling, it is confirming that voice quality, not just pitch, carries emotional meaning.
The shadow side is voice cloning. Instant voice cloning models can now reproduce a patient’s voice from under a minute of sample audio. In otolaryngology this raises immediate questions about consent in archived voice recordings, about identity in laryngectomy rehabilitation, and about deepfake-mediated fraud aimed at vulnerable patients. ENT clinicians are uniquely positioned to advise on these issues — voice is already understood in this field as a biometric.
Key Takeaways
- Emotional TTS is, mechanistically, a reverse engineering of laryngeal physiology — the same acoustic features clinicians measure in voice analysis.
- Four parameters explain most emotional variation in voice: F0, F0 range, intensity, and voice quality (jitter, shimmer, HNR).
- Anger and happiness are acoustically similar (both high-arousal); valence is mainly carried by voice quality and spectral tilt.
- Sad voice and hypofunctional dysphonia share an acoustic profile, which has implications for any AI that tries to infer emotion from voice.
- The 2024–2026 advance is the shift from emotion labels to context-aware inference — Hume Octave, ElevenLabs v3, and gpt-4o-mini-tts all derive emotion from the text itself.
- Emotional TTS is already in active use across post-laryngectomy voice banking, audiobook production, empathic mental health AI, gaming, accessibility, and conversational customer-service agents.
- AI still struggles with mid-utterance emotional transitions, individual voice quality, paralinguistic events, and non-English prosody.
FAQ
How does AI add emotion to a voice? Modern neural TTS models convert text into an emotion embedding, then generate prosody (pitch, energy, duration) and a spectral envelope conditioned on that embedding, which a vocoder turns into a waveform. The newest models (ElevenLabs v3, Hume Octave, OpenAI gpt-4o-mini-tts) infer the emotion directly from the semantic content of the text rather than requiring an explicit label.
What changes in the human voice when we feel an emotion? Sympathetic activation increases intrinsic laryngeal muscle tone — especially in the cricothyroid — which raises F0, while changes in respiratory drive shift intensity and timing. Vocal fold vibration becomes more or less regular depending on muscle tension, altering jitter, shimmer, and HNR.
Why does an angry voice sound different from a sad voice? Anger is a high-arousal state with sympathetic dominance, producing high F0, wide pitch range, fast rate, and loud, tense phonation. Sadness is a low-arousal state with reduced respiratory drive, producing low F0, narrow range, slow rate, and quiet, breathy phonation — an acoustic pattern that resembles hypofunctional dysphonia.
Where is emotional TTS being used right now? Major active applications include voice banking and personalized voice synthesis for post-laryngectomy and ALS patients, audiobook narration with consistent emotional arcs, empathic AI agents in digital mental health tools, dynamic character dialogue in games and virtual environments, accessibility tools for visually impaired users, and emotionally calibrated customer-service voice agents.
Can AI voices truly replicate human emotion? Within a single utterance with a stable emotion, modern emotional TTS is convincing enough that listeners cannot reliably distinguish it from human speech. Mid-utterance emotional transitions, individual voice quality fingerprints, and naturally timed paralinguistic events (sighs, tremor, sobs) remain noticeably weaker than human performance.
What does an ENT specialist see in this technology? Emotional TTS is synthesizing the exact acoustic parameters extracted in voice clinic analysis, which means the field is implicitly validating decades of clinical voice science. The flip side is voice cloning, which raises consent and identity questions that otolaryngologists — who understand voice as a biometric — should help society navigate.
References
- Banse R, Scherer KR. Acoustic profiles in vocal emotion expression. J Pers Soc Psychol. 1996;70(3):614-636.
- Demmink-Geertman L, Dejonckere PH. Nonorganic habitual dysphonia and autonomic dysfunction. J Voice. 2002;16(4):549-559.
- González-García M, Carrillo-Franco L, Díaz-Casares A, López-González MV, Dawid-Milner MS. Central Autonomic Mechanisms Involved in the Control of Laryngeal Activity and Vocalization. Biology (Basel). 2024;13(2):118.
- Helou LB, Wang W, Ashmore RC, Rosen CA, Abbott KV. Intrinsic laryngeal muscle activity in response to autonomic nervous system activation. Laryngoscope. 2013;123(11):2756-2761.
- Juslin PN, Laukka P. Communication of emotions in vocal expression and music performance: different channels, same code? Psychol Bull. 2003;129(5):770-814.
- Lorenc A, Sjogren EV, Karbiener M, Stankowski T, Stanek J, Welleschik B, Pospiech L, Zatonski T. Text-to-speech synthesis as an alternative communication means after total laryngectomy. Biomed Pap Med Fac Univ Palacky Olomouc Czech Repub. 2020;164(2):192-199.
- Sabour S, Zhang W, Xiao X, Zhang Y, Zheng Y, Wen J, Zhao J, Huang M. A chatbot for mental health support: exploring the impact of Emohaa on reducing mental distress in China. Front Digit Health. 2023;5:1133987.
- Tang Y, Corballis PM, Hallum LE. Acoustic Features of Emotional Vocalizations Account for Early Modulations of Event-Related Brain Potentials. Psychophysiology. 2026.
Joonpyo Hong, MD is a board-certified otolaryngologist practicing in Korea. This article reflects his clinical interpretation of published research and does not constitute individual medical advice. It is not intended to promote or endorse any specific company or product mentioned; brand names appear only as concrete examples of the technologies described.