
A convolutional neural networks in medicine can match a dermatologist on a curated dataset and still fail the patient who walks into the clinic next Monday. Understanding why is the entire field.
The modern era of medical artificial intelligence has two reasonable starting dates. The first is February 2017, when Nature published a Stanford group’s demonstration that a single convolutional neural network — a CNN — could classify skin lesions at a level comparable to twenty-one board-certified dermatologists [Esteva, Dermatologist-level classification of skin cancer with deep neural networks, 2017]. The second is December 2016, when JAMA published a Google team’s algorithm that detected referable diabetic retinopathy on retinal fundus photographs with a sensitivity above 90 percent against a panel of ophthalmologists [Gulshan, Development and Validation of a Deep Learning Algorithm for Detection of Diabetic Retinopathy, 2016]. Within a year, the message had spread across radiology, pathology, dermatology, ophthalmology, and otolaryngology: a CNN trained on enough labeled images can match a specialist on a narrow visual task.
Almost a decade later, the question has shifted. Benchmark accuracy is no longer surprising. The harder problem is whether a model that performs well on a curated test set produces any measurable benefit when it is dropped into a real clinic — where the camera is older, the lighting is worse, the patient population is different, and the physician already has fifteen minutes to see the next patient. The textbook result and the bedside result are not the same thing.
What follows is a brief tour of what a CNN actually does, two landmark studies outside otolaryngology, two studies inside it, and a sober look at what the technology can realistically promise medicine over the next decade.
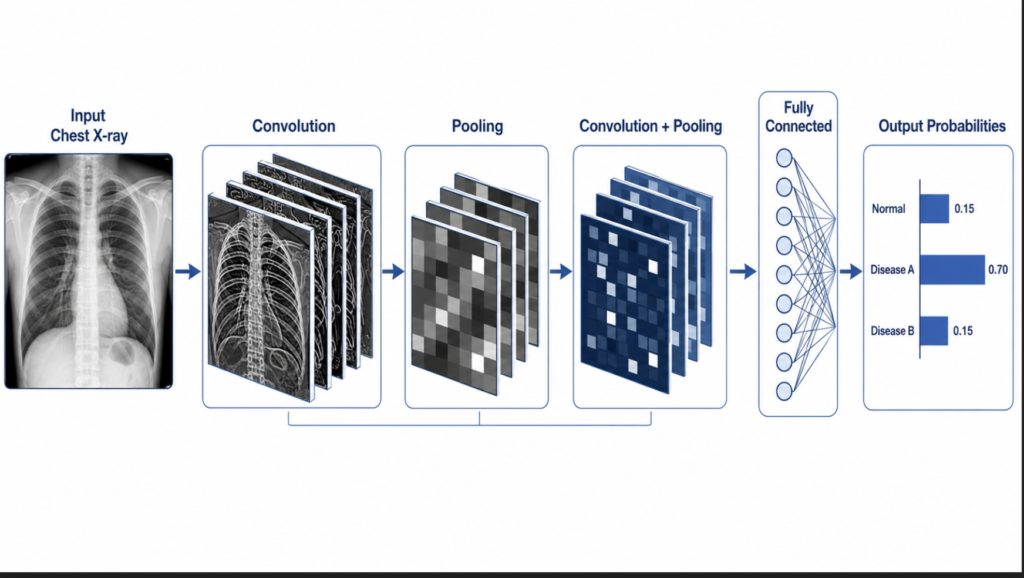
What a convolutional neural network actually does
A convolutional neural network is a particular kind of deep learning model optimized for images. The intuition is older than the name: a 1962 study by Hubel and Wiesel showed that neurons in the cat’s visual cortex respond not to whole images but to small oriented patterns within them — edges, bars, corners. A CNN is essentially a computational version of that idea, stacked many times.
The architecture is built from three repeating elements. Convolutional layers slide small filters across the image, each filter sensitive to a particular local pattern; early filters detect edges and color gradients, later filters detect curves, textures, and ultimately object parts. Pooling layers downsample these feature maps so the network captures structure at progressively coarser scales. A fully connected classification head takes the final, highly abstract feature vector and assigns it to one of several categories — for example, benign nevus versus melanoma.
What makes this useful in medicine is that the network learns its filters from data rather than from a human-written rulebook. Earlier computer-aided diagnosis systems required engineers to specify, in advance, which textures or color patterns mattered for which disease. A modern CNN is shown hundreds of thousands of labeled images and discovers those features itself. Two practical consequences follow. First, performance scales with data: a CNN trained on a hundred thousand images will, in general, outperform one trained on a thousand. Second, the features the network learns may be invisible to the clinician — accuracy can be high even when interpretability is low.
Almost every medical imaging modality has been shown to be tractable: chest radiographs, mammograms, retinal photographs, histopathology slides, dermoscopic images, otoscopic photographs, laryngoscopic frames. The common condition is straightforward: enough labeled examples, a defined classification task, and reasonably consistent image acquisition.
Clinical Perspective. The strength of a CNN is also its weakness. It learns whatever patterns separate the labeled classes in its training set — including patterns the developers did not intend. A model that “diagnoses” disease may in fact be detecting the brand of camera, the type of ruler in the corner of the image, or the hospital’s tagging convention. Diagnostic claims about a CNN are claims about a specific dataset, not about the disease.
Two landmark studies outside otolaryngology
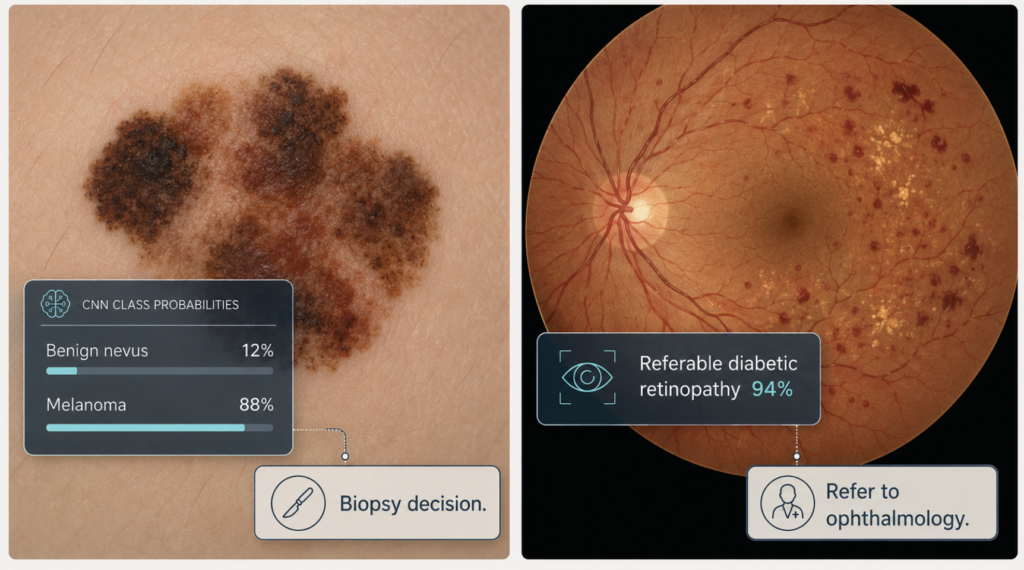
Esteva 2017: dermatologist-level classification of skin cancer
The Stanford study used 129,450 clinical images covering more than two thousand skin diseases, drawn from eighteen online sources and Stanford’s own dermatology clinic [Esteva, 2017]. The network architecture was Google’s Inception v3, originally trained on the ImageNet corpus of natural photographs (cats, cars, mushrooms) and then fine-tuned on the skin-image dataset — a standard technique known as transfer learning.
Two clinical tasks were evaluated. The first distinguished keratinocyte carcinomas from benign seborrheic keratosis. The second, more consequential task distinguished malignant melanomas from benign nevi, the diagnostic question on which biopsy decisions hinge. Against twenty-one board-certified dermatologists scoring the same test images, the CNN matched expert performance on both tasks, with area-under-the-curve values around 0.96 [Esteva, 2017].
The result drew a sharp public reaction in part because the input was nothing more than the pixels of a photograph and a diagnostic label — no engineered features, no patient history, no clinical context. A general-purpose vision model, retrained on dermatology images, performed at the level of physicians who had completed a multi-year residency.
What the paper did not establish is whether such a system, deployed in primary care or on a smartphone, would improve actual patient outcomes. The test images were curated, dermoscopic or clinical-grade, and labeled by experts. The patient who photographs a back lesion on an iPhone in evening light is not the patient in the Stanford test set.
Gulshan 2016: deep learning for diabetic retinopathy
The Google study trained a deep CNN on 128,175 retinal fundus photographs, each graded multiple times by U.S.-licensed ophthalmologists and senior residents [Gulshan, Development and Validation of a Deep Learning Algorithm for Detection of Diabetic Retinopathy, 2016]. The clinical task was binary in a useful way: detect referable diabetic retinopathy — moderate or worse retinopathy, or referable macular edema — in patients whose disease, untreated, can progress to blindness.
The algorithm was tested on two independent datasets. On EyePACS-1, at an operating point chosen for high specificity, the model achieved a sensitivity of 90.3 percent and a specificity of 98.1 percent [Gulshan, 2016]. On the Messidor-2 dataset, performance was comparable. Translated into plain language: the model missed roughly one in ten patients who needed referral, and almost never raised a false alarm. Either error mode matters. A miss delays treatment; a false alarm wastes a specialist visit. But because referable retinopathy is comparatively rare and ophthalmologist time is scarce, the cost asymmetry favors high specificity.
The clinical premise behind this study was not “replace the ophthalmologist.” It was that more than four hundred million people worldwide have diabetes, and most of them, especially in low- and middle-income countries, have no realistic access to retinal screening. A model that can run on a fundus camera in a primary care clinic or a pharmacy in Madurai or Nairobi addresses a problem the global supply of ophthalmologists cannot.
Clinical Perspective. The Esteva and Gulshan papers are best read together. One shows that a CNN can match specialists on a hard visual task. The other shows that a CNN may matter most where specialists are absent. The clinical value is not “outperform the expert in the room”; it is “function in the room that has no expert.”
Two cases in otolaryngology
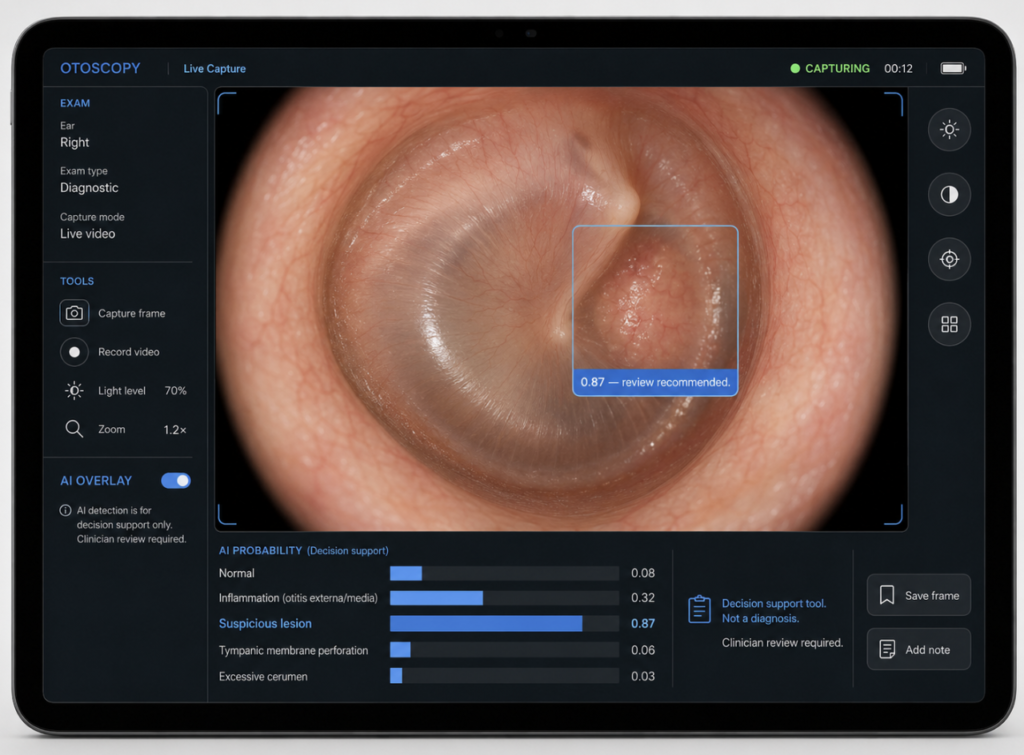
Cha 2019: ensemble CNN for ear disease on otoendoscopy
A team at Yonsei University Severance Hospital trained nine convolutional architectures on 10,544 otoendoscopic images and then combined the two best-performing models into an ensemble classifier [Cha, Automated diagnosis of ear disease using ensemble deep learning with a big otoendoscopy image database, 2019]. The six clinical categories chosen were practical rather than theoretical: normal, attic retraction, tympanic membrane perforation, otitis externa with or without myringitis, middle ear tumor, and chronic otitis media. These are the classes that drive real referral and surgical decisions.
The ensemble model classified images across the six categories with overall accuracy in the high ninetieth percentile on the test set [Cha, 2019]. More importantly, the model was trained on images drawn from routine clinical practice rather than a curated atlas — different ear shapes, different cerumen, different inflammatory backgrounds. This is closer to the diagnostic noise an otolaryngologist actually sees.
The clinical promise here is unrelated to expert replacement. In Korea and many other countries, the primary-care examination of children’s ears is performed by pediatricians and general practitioners with otoscopes whose diagnostic agreement with otolaryngologists is, in published studies, moderate at best. A CNN running on a smartphone-attached otoscope could, in principle, raise the floor of that examination — flag the eardrum that warrants specialist attention and reassure the family of the eardrum that does not.
Xiong 2019: laryngeal cancer detection on laryngoscopy
The same year, a multicenter team in China trained a deep CNN on 13,721 laryngoscopic images from two tertiary hospitals, with four diagnostic classes: laryngeal cancer (LCA), precancerous laryngeal lesions (PRELCA), benign laryngeal tumors (BLT), and normal tissue (NORM) [Xiong, Computer-aided diagnosis of laryngeal cancer via deep learning based on laryngoscopic images, 2019]. Validation used 1,176 images from three additional hospitals, so the testing institutions were entirely separate from the training ones — an external validation, not an internal one.
For the binary task of separating urgent cases (cancer or precancer) from non-urgent ones, the model reached a sensitivity of 0.731, a specificity of 0.922, and an area under the curve of 0.922 [Xiong, 2019]. Compared against three endoscopists with three, ten, and twenty years of experience, the model’s performance was comparable to the senior expert and exceeded the junior one.
Two features of this study deserve emphasis. First, external validation is the hard test, and the model survived it. Second, the sensitivity figure — 73 percent — is honest. In a screening context, missing nearly three in ten cancers is not acceptable as a standalone decision; the model’s role is to assist the endoscopist, not to gate the biopsy. A laryngoscopic CNN is a second pair of eyes, not a substitute for them.
Clinical Perspective. Both otolaryngology studies share a quiet clinical realism. Neither team claims that a CNN should make the final diagnosis. Both position the model as a triage layer — useful in raising suspicion, useful in flagging the image worth a closer look, less useful as a final decision-maker. This is the right framing for almost every CNN deployment in medicine today.
What Convolutional Neural Networks in Medicine realistically promises
The next decade of CNN-in-medicine is unlikely to look like the next decade of CNN-in-medicine that the popular press has been promising since 2017. It will not be physician replacement; it will be a quieter, more structural reshaping of where expertise lives in the healthcare system.
Three realistic directions:
Screening at the periphery. The most defensible CNN deployments are in places where the alternative is no examination at all. A CNN-assisted retinal camera in a diabetes clinic with no on-site ophthalmologist. A CNN-assisted otoscope in a rural pediatric clinic. A CNN-assisted dermatology triage tool in a primary care office in a region with months-long dermatology waiting lists. The model does not replace the specialist; it filters who needs the specialist.
Workflow assistance for specialists. A CNN that reads a chest X-ray before the radiologist does not replace the radiologist — it changes the order in which images are read, surfaces the films that look urgent, and shrinks the time-to-report for time-sensitive findings. The same logic applies to laryngeal cancer screening clinics, otology referral centers, and dermatology clinics. The model becomes a triage layer above the human, not a competitor beside the human.
Standardization of variable practice. Inter-observer agreement among physicians is often poorer than the literature suggests. A well-validated CNN, applied consistently across cases, can act as a reference standard against which physician variability is measured. In the long run this may matter more than any single diagnostic accuracy number.
What CNN will not easily solve is also worth stating clearly. Distribution shift — the gap between the training set and the deployment site — remains the single largest barrier to clinical translation. A model trained on Korean otoendoscopy images may underperform on Ethiopian children. A model trained on Stanford dermatology photographs may underperform on darker skin tones. Regulatory questions, especially around continuous-learning models, remain unsettled. Medico-legal liability, when a CNN’s silence contributes to a missed diagnosis, remains unsettled. None of these problems are solved by better accuracy on a test set.
Clinical Perspective. The honest answer about CNN in medicine is that the technology has crossed its first threshold — it can match specialists on narrow tasks — and is now stuck at the second, which is harder. The second threshold is integration: deployment in clinics, workflows, and care models that translate accuracy into outcomes. The first threshold required compute and data. The second requires regulation, infrastructure, and clinical patience. The benchmark is solved. The bedside is not.
Key Takeaways
- A convolutional neural network is a deep learning model that learns its visual filters from data, making it well-suited to medical imaging tasks where labeled examples are abundant.
- The 2016 JAMA diabetic retinopathy study and the 2017 Nature skin cancer study established that a CNN can match specialist performance on narrow visual tasks given sufficient training data.
- In otolaryngology, ensemble CNNs have classified otoendoscopic images across six clinical categories at high accuracy, and externally validated models have detected laryngeal cancer at the level of senior endoscopists.
- Benchmark accuracy is not the same as clinical utility; a model that excels on a curated test set may fail on a different camera, a different population, or a different clinical workflow.
- The realistic short-term value of CNN in medicine is screening at the periphery, workflow triage for specialists, and standardization of variable practice — not autonomous diagnosis.
- Distribution shift, regulation, and liability — not accuracy — are now the rate-limiting steps for clinical translation.
FAQ
Can a CNN replace a specialist in diagnosing skin or eye disease? No. Studies such as Esteva 2017 and Gulshan 2016 demonstrated specialist-level accuracy on curated test sets, but no published evidence shows that an unsupervised CNN can replace clinical judgment in real practice [Gulshan, 2016]. The realistic role is triage and screening, particularly where specialists are unavailable.
Why does an otolaryngology CNN typically use only a few thousand images, while dermatology CNNs use hundreds of thousands? Otoscopic and laryngoscopic images are harder to obtain at scale than dermatology photographs, since the relevant anatomy is internal and the imaging device is specialized. The Cha 2019 study assembled 10,544 otoendoscopic images, a large dataset by otolaryngology standards [Cha, 2019]. Larger ENT datasets remain a bottleneck for the field.
How accurate is a CNN at detecting laryngeal cancer compared with a human endoscopist? Comparable to a senior endoscopist for the binary task of urgent versus non-urgent lesions, but with sensitivity around 73 percent on external validation [Xiong, 2019]. That figure is honest about the model’s limits — it is a useful assist, not a standalone screening tool.
What is the main obstacle to wider clinical use of CNNs in medicine? Distribution shift — the difference between training data and real-world clinical data — together with regulatory and liability uncertainty. Accuracy on a benchmark dataset is necessary but not sufficient for clinical deployment.
References
- Esteva A, Kuprel B, Novoa RA, Ko J, Swetter SM, Blau HM, Thrun S. Dermatologist-level classification of skin cancer with deep neural networks. Nature. 2017;542(7639):115-118.
- Gulshan V, Peng L, Coram M, Stumpe MC, Wu D, Narayanaswamy A, Venugopalan S, Widner K, Madams T, Cuadros J, Kim R, Raman R, Nelson PC, Mega JL, Webster DR. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA. 2016;316(22):2402-2410.
- Cha D, Pae C, Seong SB, Choi JY, Park HJ. Automated diagnosis of ear disease using ensemble deep learning with a big otoendoscopy image database. EBioMedicine. 2019;45:606-614.
- Xiong H, Lin P, Yu JG, Ye J, Xiao L, Tao Y, Jiang Z, Lin W, Liu M, Xu J, Hu W, Lu Y, Liu H, Li Y, Zheng Y, Yang H. Computer-aided diagnosis of laryngeal cancer via deep learning based on laryngoscopic images. EBioMedicine. 2019;48:92-99.
- LeCun Y, Bengio Y, Hinton G. Deep learning. Nature. 2015;521(7553):436-444.
Joonpyo Hong, MD is a board-certified otolaryngologist practicing in Korea. This article reflects his clinical interpretation of published research and does not constitute individual medical advice.
This article is not intended to advertise or promote any specific company or product.
For more interesting contents:
https://curiousmd.com/cnn-laryngeal-cancer-diagnosis/
https://curiousmd.com/ai-laryngeal-cancer-detection/
https://curiousmd.com/deviated-septum-diagnosis-ai/
https://curiousmd.com/ai-speech-clarification-hearing-loss/
Link out to:
https://doi.org/10.1038/nature21056
https://doi.org/10.1001/jama.2016.17216
https://doi.org/10.1016/j.ebiom.2019.06.050
https://doi.org/10.1016/j.ebiom.2019.08.075
https://doi.org/10.1038/nature14539
https://www.fda.gov/medical-devices/software-medical-device-samd/artificial-intelligence-software-medical-device