
The future of clinical decision support is not about searching medical knowledge faster. It is about modeling each patient as the primary object of clinical reasoning. Four AI paradigms are racing to replace the textbook — and they are not waiting for medicine to catch up.
A 50-year-old man presents to ENT clinic with unilateral sudden sensorineural hearing loss, 72 hours after symptom onset. His HbA1c is 7.5%. His BMI is 34. Two months ago he had a coronary stent placed and he is on dual antiplatelet therapy. The American Academy of Otolaryngology–Head and Neck Surgery guideline recommends high-dose systemic corticosteroids as first-line therapy. By the textbook, the answer is straightforward.
The honest answer is: it depends. Doctors would deliberate between oral systemic steroid and intratympanic steroid administration, weighing systemic risk against efficacy at the cochlea. The corticosteroid evidence base in SSNHL is derived mainly from trials that often exclude or underrepresent patients at higher systemic risk, such as those with poorly controlled diabetes or recent major cardiovascular events, so safety and efficacy data in these populations are limited. The textbook describes what works for an average patient. This patient is not that patient. No real patient ever is.
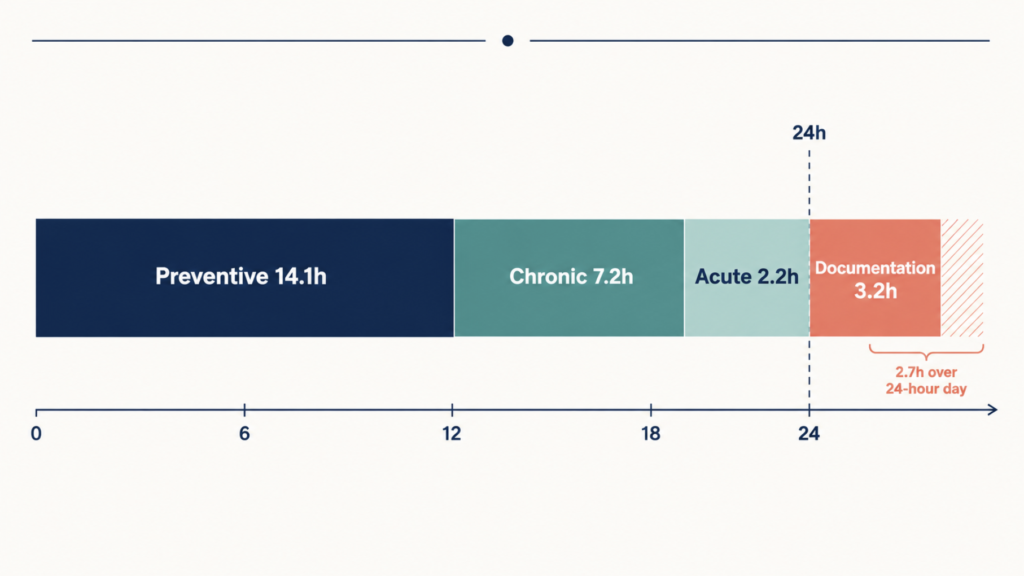
A simulation study from the University of Chicago, Johns Hopkins, and Imperial College London made this concrete in a way the medical community is still digesting. If a primary care physician followed every preventive, chronic, and acute care guideline for an average panel of 2,500 adults, the workday required would be 26.7 hours. Even with team-based care, the number only drops to 9.3 hours [Porter J, Revisiting the Time Needed to Provide Adult Primary Care, 2023]. There are not enough hours in the day to be a textbook clinician.
More guidelines are not the answer. A different way to model the patient is. Four AI paradigms are now competing to replace the textbook as the primary substrate of clinical reasoning. This is a guided tour of all four, written for clinicians and the people building the tools they will use.
Why the Textbook Breaks at the Bedside
The myth of the average patient
Randomized controlled trials are designed for internal validity. Inclusion criteria are narrow on purpose: a clean signal beats a noisy one. The patient who exactly matches the trial population is rare in the actual clinic. Bridging this gap between trial efficacy and real-world effectiveness is one of the most-cited reasons clinicians fail to follow guidelines, even when they want to.
In ENT, the AAO-HNS sudden sensorineural hearing loss guideline is a textbook example of textbook limits. It is a careful, evidence-graded document. It also assumes a patient whose only relevant problem is the ear. The case above has at least three other relevant problems that shift the steroid risk-benefit calculus, and the guideline does not specify how to weigh them against the standard recommendation.
The 26.7-hour problem
The Porter et al. study is not really about primary care. It is about an entire profession’s relationship with knowledge. Guidelines have multiplied. Hours in the day have not. The result is silent rationing: doctors do what they can, and the rest goes undone. Patients sense it as inattention. The reality is structural.
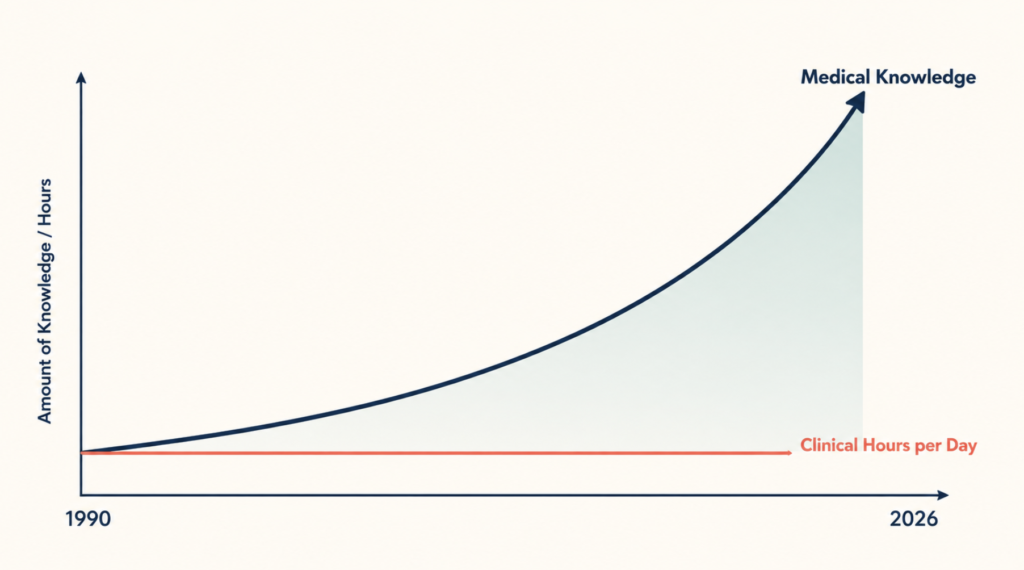
This is why “just train doctors better” is a category error. The constraint is not knowledge transfer. It is the cognitive bandwidth of the clinician at the point of care.
Why current decision support is not enough
The first generation of clinical decision support tried to solve this with curated references. UpToDate, founded in 1992, did this brilliantly and is now used by over three million health professionals worldwide. But the model still pushes the burden of search, synthesis, and contextualization onto the clinician. You have to know what to look up.
The second generation pivoted to conversational AI. OpenEvidence reached one million physician consultations in a single day in March 2026. Glass Health combines clinical reasoning with documentation. These are real improvements. They still mostly answer the questions the clinician thinks to ask.
The third generation, in academic AI labs, has spent a remarkable couple of years proving that large language models can match or beat physicians on board exam questions and structured cases. The Stanford-Harvard ARISE network’s State of Clinical AI 2026 report tempered the excitement: a systematic review of more than 500 medical AI studies found that nearly half tested models on exam-style questions and only five percent used real patient data [Bedi S, Testing and evaluation of health care applications of large language models: a systematic review, 2025]. The same body of work documented that when researchers altered standard medical multiple-choice questions so the correct answer became “none of the above” — preserving the underlying clinical reasoning — accuracy fell substantially across leading systems, in some cases by more than a third.
The problem is not the models. The problem is that all three generations of CDS still treat the patient as a search query against a body of knowledge. What is actually needed is a system that treats the patient as the primary object of reasoning, and knowledge as something that gets applied to the patient — not the other way around. Four paradigms are attempting this inversion.
Paradigm 1: Patient as Object — The Ontology Approach
What Palantir Foundry actually does in a hospital
Palantir Foundry is not a clinical product. It is a general-purpose data platform whose central idea is the ontology: a layer that maps scattered data sources to first-class objects representing things in the real world. In a hospital deployment, those objects are Patient, Encounter, Order, Lab, Bed, Provider, and the relationships between them.
Once a patient is a proper object rather than rows in twenty different tables, something powerful becomes possible. A clinician can ask a question and the system can answer it by traversing the patient’s object graph, not by running a SQL query against denormalized data.
The case studies
Tampa General Hospital deployed Foundry as its operational data foundation in 2022, using the ontology to integrate clinical, operational, and research workflows. The NHS in England is rolling out Foundry as the Federated Data Platform across hospital trusts. Chelsea and Westminster Hospital reported a 28% reduction in its inpatient waiting list after implementation, driven primarily by giving clinicians and planners a coherent view of the same underlying objects.
Why this matters for decision-making
The interesting move is not the dashboards. It is that a guideline can be re-expressed as a rule against the ontology. “Recommend oral systemic corticosteroids for SSNHL within 14 days of onset unless patient.HasCondition(suboptimallyControlledDM) OR patient.OnMedication(DAPT) OR patient.RecentEvent(cardiacStent, within=90d), in which case prefer intratympanic route.” This is declarative, auditable, and patient-specific. The textbook becomes executable.
Limitations
Foundry’s ontology is operational gold and clinical reasoning bronze. It excels at integrating heterogeneous data; it does not by itself contain medical knowledge. The clinical rules still have to be written, validated, and maintained. There are also legitimate concerns about data governance and the concentration of national health data in a single vendor’s platform — concerns that vary by country and political moment. The conceptual contribution stands regardless: the patient should be an object, not a query.
Paradigm 2: Patient as Trajectory — Epic Cosmos and CoMET
The scale that nothing else has
Epic Systems, the EHR vendor with about 38% of US inpatient market share, launched Cosmos in 2019 as a de-identified longitudinal dataset built from participating health systems. As of August 2025, Cosmos contains records from approximately 300 million unique patients across more than 1,760 hospitals, totaling 16.3 billion encounters. No other healthcare dataset in the world is at this scale.
In 2025, Epic, Microsoft Research, and Yale School of Medicine published a technical report on the Cosmos Medical Event Transformer (CoMET): a family of decoder-only transformer models pretrained on 118 million patients and 151 billion tokens of medical events. In March 2026, Epic introduced Curiosity, a generative AI family built on Cosmos designed to simulate future patient outcomes.
The conceptual leap
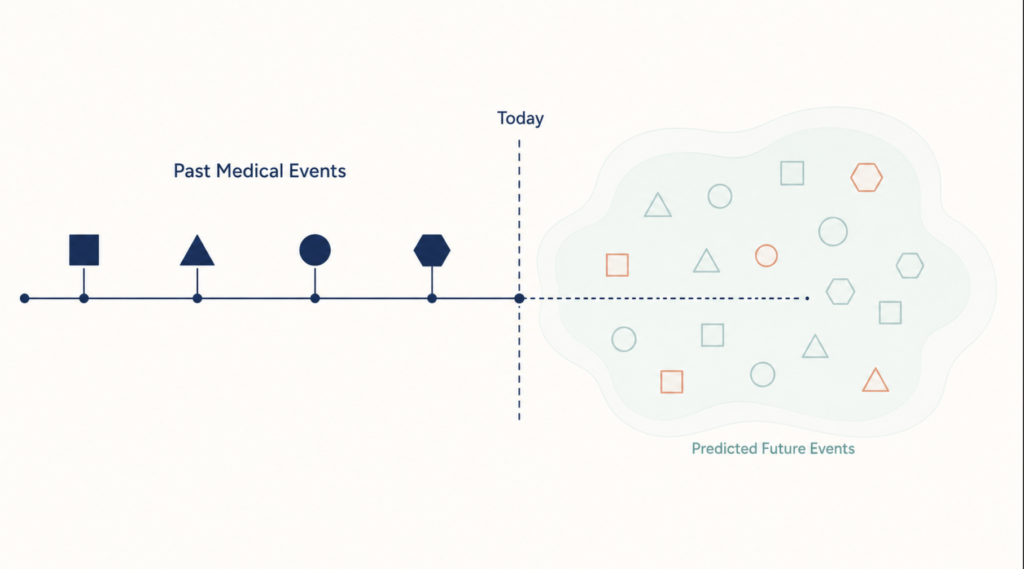
CoMET is not a chatbot. It is a foundation model trained the same way GPT was — by predicting the next token in a sequence — but the tokens are medical events: a diagnosis code, a lab result, a medication, a procedure, an encounter. Given any patient’s history up to today, it can predict probable future events.
This inverts the textbook model in a specific way. Evidence-based medicine takes a population (the trial cohort) and applies its average outcome to this patient. CoMET takes this patient’s trajectory and finds the empirical neighborhood of similar trajectories already lived by millions of others. The reference point is no longer the abstract Platonic patient. It is the patients who actually looked like yours.
What it changes in practice
Consider how the system might analyze the SSNHL case above. CoMET would not consult the guideline. It would look at the cohort of similar patients in Cosmos — middle-aged men with suboptimally controlled diabetes, recent coronary intervention, on DAPT, presenting with unilateral SSNHL within 72 hours — and report what actually happened to them, by treatment received. A guideline says what should work. CoMET shows what did work, in patients with comparable profiles. These are not the same thing.
Limitations
Cosmos is locked to institutions using Epic. Its de-identification is governed by a peer-elected council, but the data is still operationally owned by a private vendor. The model’s reasoning is harder to interrogate than a rule-based ontology — it is a learned function, not a declarative system. And trajectory prediction inherits the biases of historical care: if a population was historically undertreated, the trajectories will reflect undertreatment, not optimal care. Cosmos AI Lab is scheduled to open to outside researchers in February 2026, which will help test these concerns.
Paradigm 3: Patient as Simulation — Digital Twins
From visualization to in silico testing
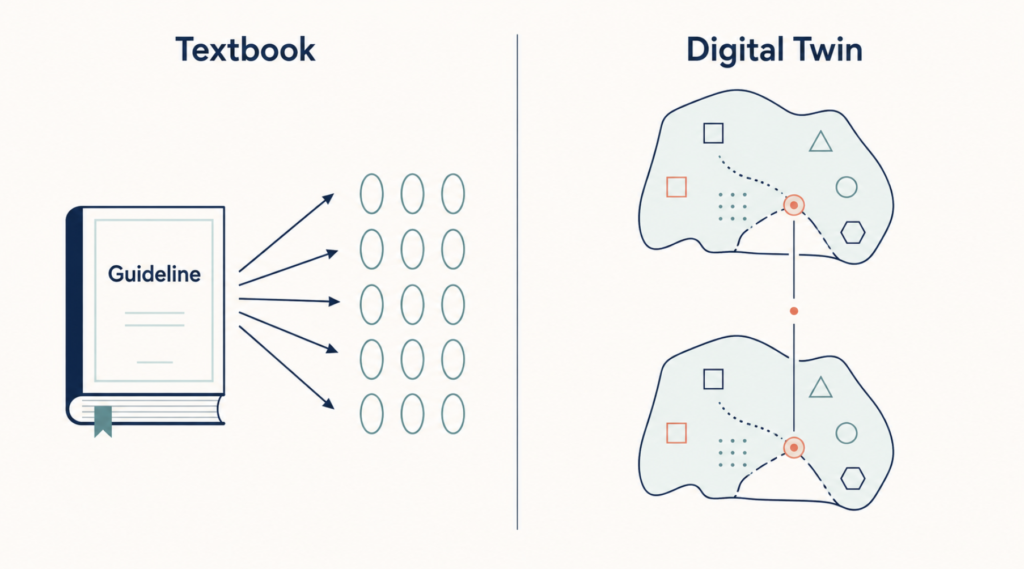
A digital twin in medicine is a virtual replica of a specific patient’s physiology, built from EHR data, imaging, biomarkers, and increasingly from wearables. Unlike a dashboard, a twin is executable: interventions can be run against it and outcomes simulated before anything is applied to the real patient.
The most mature examples are in cardiology. Dassault Systèmes’ Living Heart Project has built increasingly anatomically accurate computational models of the human heart, used in cardiac device design and translational research. In September 2025, Mayo Clinic and Siemens Healthineers announced a partnership to develop AI-enhanced cardiovascular digital twins for individualized risk prediction. Mayo Clinic also has digital twin work underway for predicting the first 24-hour response of critically ill patients to sepsis treatment.
Regulatory tailwind
The technology took a step toward regulatory legitimacy in January 2025, when the US FDA issued draft guidance on AI-supported regulatory decision-making that explicitly addressed digital twins and virtual patient simulations as part of the evidence framework for drug and biological products. This was a quiet milestone. A federal regulator naming in silico evidence in formal guidance is a structural change in how medicine accepts its evidence.
Mayo Clinic’s Mayo Clinic Proceedings devoted a position paper in October 2025 to the role of AI in individualized medicine, explicitly framing the digital twin as a core mechanism for personalizing prevention, diagnosis, and treatment [Lazaridis KN, Individualized Medicine in the Era of Artificial Intelligence, 2025].
What it changes at the bedside
For the SSNHL case described, the relevant question is not “what did the trial population do on steroids?” It is “what will happen to this specific cochlea, in this specific diabetic, antiplatelet-dosed body, if steroids are administered?” That is a question a sufficiently good twin can model. Most ENT applications are not there yet. The direction, however, is clearly set.
Limitations
Digital twins are computationally expensive and only as good as the physiology they encode. Cardiovascular and metabolic systems are well-modeled; immune, psychiatric, and many ENT systems are not. Validating a twin against the patient it represents — a patient who exists in only one trajectory of reality — is methodologically hard. The FDA guidance is draft, not final. And there is no consensus on what a twin should report to a clinician without overwhelming them.
Paradigm 4: Patient as Knowledge Graph — Agentic Medical KG
The hallucination problem and the multi-hop problem
Large language models, even excellent ones, have two persistent failure modes in medicine. They confabulate. And they struggle with multi-hop reasoning — the kind of inference a clinician does naturally when chaining “this drug interacts with that enzyme, which is induced by this comorbidity, which is more common in this demographic.”
A growing body of academic work argues that grounding LLMs in evolving medical knowledge graphs solves both. The Agentic Medical Knowledge Graph–Retrieval-Augmented Generation framework (AMG-RAG), presented at EMNLP 2025, showed that LLMs paired with a dynamically updated medical knowledge graph outperformed pure LLMs on MEDQA and related benchmarks by meaningful margins, with reduced hallucination rates.
The agentic part
The “agentic” in AMG-RAG is the second contribution. Rather than answering in one pass, an agent traverses the graph in steps, retrieves evidence at each step, and reasons across hops. This produces a reasoning trace that a clinician can inspect — not a black box answer but a chain of justifications grounded in cited sources.
Where it sits today
This paradigm is the least commercially mature of the four. It is most visible in academic work and in specialty applications. Tempus has built something like a clinical-molecular-outcomes graph for oncology that informs treatment selection. For most other specialties, the agentic KG approach is still pre-product. But the trajectory matters: the moment a multi-hop reasoning system with provenance becomes reliable enough to embed in workflow, it solves problems the other three paradigms struggle with.
When the Paradigms Blur
The four paradigms have been drawn here as clean separations because the clean version is useful for thinking. The dirty version is that they are converging.
Palantir began describing Foundry’s ontology layer as a “digital twin” in late 2025 — the same conceptual claim Mayo Clinic makes for its cardiac twin, dressed in different vocabulary. Epic Cosmos uses both trajectory prediction (CoMET) and graph-structured medical event representations. Academic agentic KG systems are increasingly trained on trajectory data drawn from de-identified EHRs.
The right way to read the field is not as four competing visions but as four lenses on the same underlying claim: clinical decisions should be made against a structured, executable, queryable model of this specific patient, with general medical knowledge applied to that model rather than the patient being squeezed into the average. The lenses differ in what they emphasize — the ontology lens emphasizes structure and explicit rules, the trajectory lens emphasizes empirical regularities, the twin lens emphasizes physiology, the graph lens emphasizes multi-hop inference. Real systems will combine all four.
Clinical Perspective: An ENT Specialist’s Take
ENT is an unusually good testbed for this transition, and adoption here may move faster than the general literature predicts. The reason is the data shape. Otolaryngology decisions are multimodal almost by definition — audiometry, tympanometry, vestibular testing, imaging, endoscopy, voice and speech metrics, increasingly intraoperative neural recordings during cochlear implantation, the layered surgical difficulty of head and neck cancer resection where margins, nerves, and vascular structures must be reconciled in real time, the geometric and biological design of free-flap reconstruction, and so on. No single modality drives the call. The clinician integrates them in their head.
A patient-as-object representation handles this integration explicitly, which is a feature, not a threat to clinical autonomy. The AAO-HNS Artificial Intelligence Task Force report set out the principles for safe integration in 2025, emphasizing transparency, clinician judgment, and human-in-the-loop oversight as non-negotiables [Ayoub NF, American Academy of Otolaryngology-Head and Neck Surgery (AAO-HNS) Report on Artificial Intelligence, 2025]. Those principles map cleanly onto the ontology and knowledge graph paradigms, which produce auditable reasoning traces. They map less cleanly onto pure trajectory models, where the reasoning is implicit in the learned weights. This is a real tension and it will get worked out application by application.
A plausible vision of the ENT clinic of 2030 is a hybrid of paradigms 2 and 3. A trajectory model surfaces what happened to similar patients. A specialty-specific digital twin — of the cochlea, of the larynx, of the thyroid bed — predicts what is likely to happen when a particular intervention is applied to a particular anatomy. A knowledge graph layer keeps both honest by exposing the citations behind the recommendations. And an ontology layer holds the patient as a stable, structured object across the whole stack.
The textbook does not disappear. It becomes the audit trail. Guidelines remain the social contract — what the profession agrees is reasonable practice. The question shifts from “what does the guideline say to do” to “what does the guideline say to do, and how does that apply to this specific patient as modeled in the system.” Done right, the 26.7-hour problem becomes solvable. Done wrong, the result is the most expensive overlay in the history of clinical computing.
Key Takeaways
- Following every clinical guideline for an average primary care panel would require 26.7 hours a day, demonstrating that the limit on guideline-based care is not knowledge but cognitive bandwidth at the point of care.
- Four AI paradigms are competing to replace textbook decision-making: patient-as-object (Palantir Foundry), patient-as-trajectory (Epic Cosmos and CoMET), patient-as-simulation (digital twins at Mayo, Siemens, Dassault), and patient-as-knowledge-graph (agentic medical KG systems).
- Epic Cosmos covers 300 million patients across 1,760 hospitals and trains foundation models that predict the next likely medical event for a specific patient based on similar real trajectories.
- The FDA issued draft guidance in January 2025 addressing AI-supported regulatory decision-making for drug and biological products that explicitly names digital twins and virtual patients, signaling growing acceptance of in silico reasoning.
- The four paradigms are converging rather than competing; the real shift is from squeezing patients into population averages to building structured, executable, patient-specific models against which medical knowledge is applied.
- ENT is well-suited as an early adopter because its decisions are multimodal and time-sensitive, and the AAO-HNS AI Task Force has set clinician-in-the-loop principles that align with the more auditable paradigms.
FAQ
Why don’t clinical guidelines work in real practice? Clinical guidelines are derived from randomized trials with narrow inclusion criteria, but real patients have comorbidities, social context, and individual preferences the trials excluded. A simulation study found that following every preventive, chronic, and acute care guideline for an average adult primary care panel would require 26.7 hours per day [Porter J, Revisiting the Time Needed to Provide Adult Primary Care, 2023]. The constraint is cognitive bandwidth at the point of care, not knowledge access.
What is Epic Cosmos and how does it work? Epic Cosmos is a de-identified longitudinal health dataset built from participating Epic-using health systems, containing records from approximately 300 million unique patients across more than 1,760 US hospitals and 16.3 billion encounters as of August 2025. Epic, Microsoft Research, and Yale used it to train CoMET, a foundation model that predicts future medical events for a specific patient based on the trajectories of similar patients. Cosmos AI Lab is scheduled to open to outside researchers in February 2026.
What is a digital twin in medicine? A medical digital twin is a virtual replica of a specific patient’s physiology built from EHR data, imaging, biomarkers, and wearable signals. Clinicians can simulate treatment responses on the twin before applying them to the real patient. In January 2025, the US FDA issued draft guidance on AI-supported regulatory decision-making for drug and biological products that explicitly addresses digital twins and virtual patients. The most mature applications are in cardiology, including the Mayo Clinic–Siemens Healthineers partnership announced in September 2025.
What is the difference between Epic Cosmos and Palantir Foundry in healthcare? Epic Cosmos is an EHR-native clinical dataset and foundation model platform focused on predicting individual patient trajectories from historical data. Palantir Foundry is a general-purpose data platform whose ontology layer models patients, encounters, and orders as first-class objects, used by NHS England as the Federated Data Platform and by Tampa General Hospital for clinical and operational decisions. Cosmos emphasizes trajectory prediction; Foundry emphasizes structured object representation and rule-based reasoning. They are increasingly converging.
Joonpyo Hong, MD is a board-certified otolaryngologist practicing in Korea. This article reflects his clinical interpretation of published research and does not constitute individual medical advice.This post is not intended to promote or advertise any specific company
References
Ayoub NF, Rameau A, Brenner MJ, Bur AM, Ator GA, Briggs SE, Takashima M, Stankovic KM; AAO-HNS Artificial Intelligence Task Force. American Academy of Otolaryngology-Head and Neck Surgery (AAO-HNS) Report on Artificial Intelligence. Otolaryngol Head Neck Surg. 2025;172(2):734-743. PMID: 39666770.
Bedi S, Liu Y, Orr-Ewing L, et al. Testing and evaluation of health care applications of large language models: a systematic review. JAMA. 2025;333(4):319-328. PMID: 39405325.
Lazaridis KN, Klee EW, Curry TB, Ortega VE, et al. Individualized Medicine in the Era of Artificial Intelligence. Mayo Clin Proc. 2025. PMID: 41037050.
Porter J, Boyd C, Skandari MR, Laiteerapong N. Revisiting the Time Needed to Provide Adult Primary Care. J Gen Intern Med. 2023;38(1):147-155. PMID: 35776372.
Additional Sources
Brodeur P, Goh E, Rodman A, Chen JH, et al. The State of Clinical AI 2026. ARISE Network (Stanford–Harvard), January 2026.
: https://medicine.stanford.edu/news/stories/2026/01/clinical-ai-has-boomed.html
Epic Systems, Microsoft Research, Yale School of Medicine, and Cosmos Governing Council. Generative Medical Event Models Improve with Scale (CoMET technical report). arXiv:2508.12104, August 2025.
: https://arxiv.org/abs/2508.12104
Rezaei MR, Saadati Fard R, Parker JL, Krishnan RG, Lankarany M. Agentic Medical Knowledge Graphs Enhance Medical Question Answering: Bridging the Gap Between LLMs and Evolving Medical Knowledge. Findings of EMNLP 2025.
: https://aclanthology.org/2025.findings-emnlp.679/
U.S. Food and Drug Administration. Considerations for the Use of Artificial Intelligence To Support Regulatory Decision-Making for Drug and Biological Products. Draft guidance, January 2025.
: https://www.fda.gov/regulatory-information/search-fda-guidance-documents/considerations-use-artificial-intelligence-support-regulatory-decision-making-drug-and-biological
For more interesting contents:
https://curiousmd.com/acetaminophen-vs-nsaids-evidence/
https://curiousmd.com/convolutional-neural-networks-in-medicine/
https://curiousmd.com/global-aging-and-ai-medicine/